---
frameworks:
- Pytorch
license: Apache License 2.0
tasks:
- semantic-segmentation
---
# SAM-HQ (Segment Anything in High Quality)
> [**Segment Anything in High Quality**](https://arxiv.org/abs/2306.01567)
> Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu \
> ETH Zurich & HKUST
我们提出HQ-SAM对SAM进行升级,实现高质量的零弹分割。详情请参阅我们的[论文](https://arxiv.org/abs/2306.01567)。
## SAM and HQ-SAM两者效果比较
-----------------
**SAM vs. HQ-SAM**
 # 介绍
-----------------
最近的细分模型(SAM)代表了一个巨大的飞跃,在扩大细分模型,允许强大的零射击能力和灵活的提示。尽管使用了11亿个掩模进行训练,但SAM的掩模预测质量在许多情况下都存在不足,特别是在处理结构复杂的物体时。我们提出红旗-地对空导弹,使地对空导弹具备准确分割任何目标的能力,同时保持地对空导弹原有的提示设计、效率和零弹通用性。我们的精心设计重用并保留了SAM的预训练模型权值。
**SAM**与**HQ-SAM**的定量比较
-----------------
注:对于基于框提示的评估,我们给SAM、MobileSAM和我们的HQ-SAM提供相同的图像/视频边界框,并采用SAM的单掩模输出模式。
我们提供全面的性能,模型尺寸和速度对SAM变体的比较:
# 介绍
-----------------
最近的细分模型(SAM)代表了一个巨大的飞跃,在扩大细分模型,允许强大的零射击能力和灵活的提示。尽管使用了11亿个掩模进行训练,但SAM的掩模预测质量在许多情况下都存在不足,特别是在处理结构复杂的物体时。我们提出红旗-地对空导弹,使地对空导弹具备准确分割任何目标的能力,同时保持地对空导弹原有的提示设计、效率和零弹通用性。我们的精心设计重用并保留了SAM的预训练模型权值。
**SAM**与**HQ-SAM**的定量比较
-----------------
注:对于基于框提示的评估,我们给SAM、MobileSAM和我们的HQ-SAM提供相同的图像/视频边界框,并采用SAM的单掩模输出模式。
我们提供全面的性能,模型尺寸和速度对SAM变体的比较:
 ### COCO上的各种ViT主干:
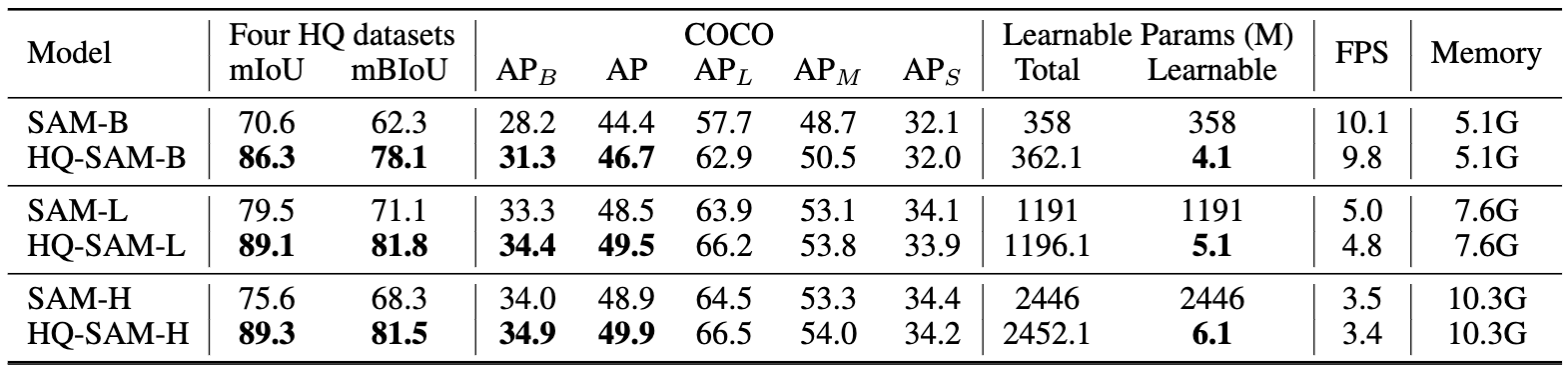
注意:对于COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器。
### YTVIS and HQ-YTVIS
注:使用vitl骨干网。我们采用在YouTubeVIS 2019数据集上训练的SOTA检测器Mask2Former作为我们的视频框提示生成器,同时重用其对象关联预测。

### DAVIS
注:使用vitl骨干网。我们采用SOTA模型XMem作为视频框提示生成器,同时重用其对象关联预测。

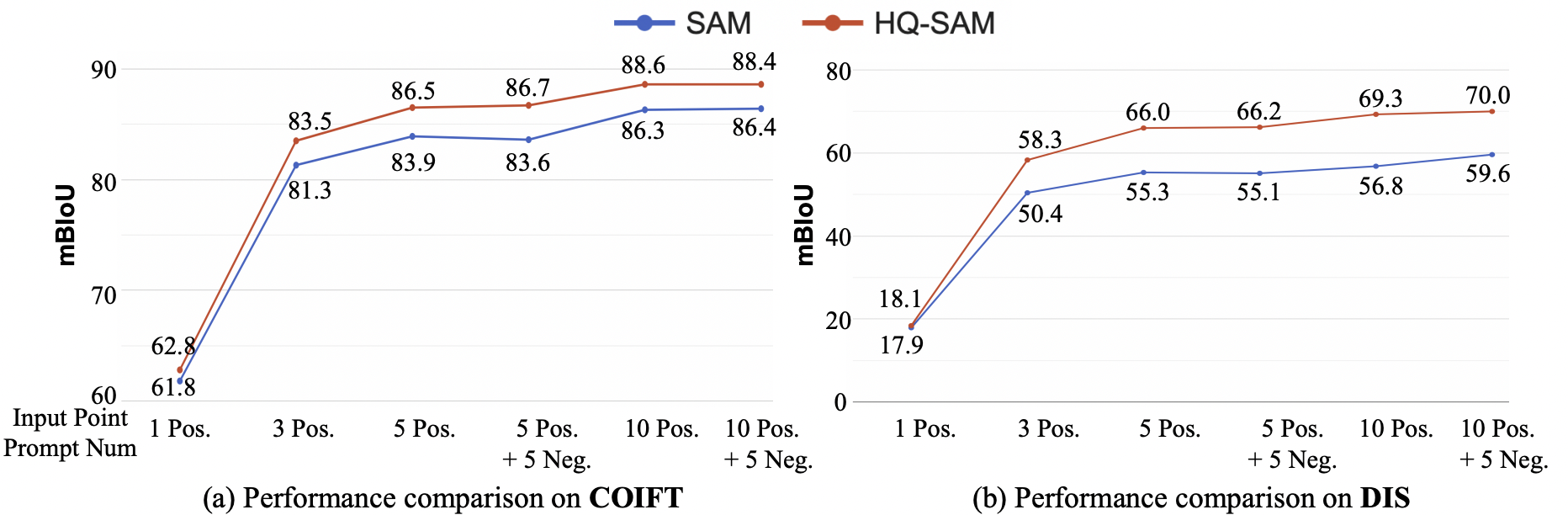
### 使用不同的点进行交互式分割比较
注:使用vitl骨干网。对高品质的COIFT(零射击)和DIS val设置。
# 引用
如果您发现HQ-SAM在您的研究中很有用,或者参考了提供的基线结果,请记得标记
```
@article{sam_hq,
title={Segment Anything in High Quality},
author={Ke, Lei and Ye, Mingqiao and Danelljan, Martin and Liu, Yifan and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
journal = {arXiv:2306.01567},
year = {2023}
}
```
### COCO上的各种ViT主干:

注意:对于COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器。
### YTVIS and HQ-YTVIS
注:使用vitl骨干网。我们采用在YouTubeVIS 2019数据集上训练的SOTA检测器Mask2Former作为我们的视频框提示生成器,同时重用其对象关联预测。

### DAVIS
注:使用vitl骨干网。我们采用SOTA模型XMem作为视频框提示生成器,同时重用其对象关联预测。

### 使用不同的点进行交互式分割比较
注:使用vitl骨干网。对高品质的COIFT(零射击)和DIS val设置。

# 引用
如果您发现HQ-SAM在您的研究中很有用,或者参考了提供的基线结果,请记得标记
```
@article{sam_hq,
title={Segment Anything in High Quality},
author={Ke, Lei and Ye, Mingqiao and Danelljan, Martin and Liu, Yifan and Tai, Yu-Wing and Tang, Chi-Keung and Yu, Fisher},
journal = {arXiv:2306.01567},
year = {2023}
}
```




